I benchmarked my own RAG system on one GPU — here's what the numbers actually said

I keep telling people that in applied AI the verification layer is the product, not the model. So I built a system that takes that literally — IW RAG, a fully-local retrieval system whose headline feature isn’t the chatbot, it’s a benchmarking studio that measures how well any configuration actually performs, on quality, speed, and VRAM, on a single GPU. Then I pointed it at itself.
This article is what it measured. But before a single number, the disclaimer that should frame all of them — because I’d rather you trust the reasoning than the digits.
Read this as educational, not as a benchmark. Every figure below was produced by IW RAG, on my own hardware — one RTX 5090 (32 GB) — against a small, synthetic, deliberately-adversarial corpus. The main run is 37 queries. That is far too small to be a published benchmark; in fact the tool’s own comparison view refuses to call a winner below 150 queries and prints an “underpowered” banner when you ask it to. Treat everything here as a worked example of how to measure, and of how a system behaves on one machine — not as a leaderboard you should cite. The value is in the method and the conclusions, not the second decimal place.
With that established: here is what I found interesting, and why.
The setup, so you can weight the numbers
One GPU, 32 GB — the binding constraint the whole design is built around. The evaluation corpus is 108 documents / 448 chunks, engineered to be hard: dozens of near-duplicate invoices, rare exact-match IDs, multi-hop questions with no shared anchor. The golden set is 37 queries. The embedder (BGE-M3) and reranker (bge-reranker-v2-m3) are held fixed across every run, and the faithfulness judge is Lynx-8B — deliberately from a different model family (Llama-3) than the Qwen generators it grades, so the judge has no stylistic self-preference for the model’s own output. A config guard enforces that the generator is never also the judge.
Sample sizes matter so much here that the studio bakes the caveat into the math: faithfulness is a binary pass/fail averaged over the run, so on 37 queries a single flipped answer moves the score by ~0.027. Anything under a ~0.05 gap is noise. Keep that in your head for everything below.
Finding 1 — retrieval is the ceiling, not the model
The most useful experiment was the most boring one: turn the retrieval pipeline on, one stage at a time, and measure recall with no LLM judge involved at all.
- Dense vector search alone: recall@10 0.691
- Add BM25 keyword search, fused with reciprocal-rank fusion: 0.713
- Add the cross-encoder reranker (the production spine): 0.779
The shape is the whole point. Hybrid search delivers the big jump in ranking quality (MRR climbs from 0.687 to 0.802); the reranker is the dominant recall lift. Neither involves a bigger or smarter generator — and that is the lesson. Across every later experiment, the thing that capped answer quality was what retrieval put in front of the model, not the model itself.
And the honest part: that 0.779 is below the 0.80 floor I set for this corpus. I did not lower the floor to make it pass. The residual misses are the multi-hop queries, which a clean synthetic set like this exposes brutally. A pass I had to fudge would tell me nothing.
Finding 2 — bigger was not better
I swapped eight local generators through the same fixed pipeline on one card — Qwen3 (8B through 32B, plus a 30B mixture-of-experts), Qwen2.5, base Llama-3.1-8B, and a fine-tune of it — and measured faithfulness and latency. Remembering the ±0.027 noise band, two results survive as real:
- More dense parameters did not help. Qwen3-32B was the slowest model in the field (≈1.8 s per query versus ≈0.6 s for the 8B) and scored no better — in fact slightly lower — on faithfulness. On this corpus, paying for 32B bought latency, not quality.
- Tuning beat size. The best faithfulness in the whole run (0.730) came from Hermes-3, an 8B fine-tune of Llama-3.1 — which comfortably out-scored its own base model (0.568). Same weights, same size; the difference was post-training.
The calculated judgment I’d actually act on: on a fixed 32 GB budget, the best generator here is a small, well-tuned one — the MoE (best quality-per-latency) or the 8B fine-tune (best faithfulness, lowest VRAM). The VRAM you save by not running a 32B is far better spent on retrieval quality and the safety guards. That’s not what you’d guess from the model-leaderboard reflex of “pick the biggest that fits.”
Finding 3 — the cheapest 10× I’ve ever measured
The quantization ladder was the clearest win. Running the same models at 4-bit AWQ with the awq_marlin kernel, versus FP8 and full bf16:
- 4-bit AWQ+Marlin was best on every axis — roughly 2.5× the throughput of bf16, ~30% less VRAM, with no measurable quality loss on this set. FP8 was the worst trade — bf16-class speed with none of the memory benefit on this GPU.
- A single, controlled A/B isolated the kernel itself: flipping the legacy
awqkernel forawq_marlintook one model from 22.8 to 225 tokens/second of decode — and turned the 32B from “times out past 120 seconds” into “answers in nine.” One flag. No quality cost.
I include this because it’s the counter-message to the rest of the piece: not every gain is hard-won judgment. Some is just measuring the boring infrastructure knob that nobody benchmarked.
Finding 4 — the result I’m most glad I kept: GraphRAG scored zero
I wired in an optional GraphRAG mode (a knowledge graph over the corpus, for multi-hop questions). Its first honest measurement: nDCG@5 of 0.000. Recall of 0.000. On every subset. The gate I’d written to decide whether to enable it returned a flat no, and the route stayed off by configuration.
The temptation in a showcase is to delete that run and never speak of it. I did the opposite — it’s in the reports. The zero turned out to be a stack of real bugs plus a naive entity-matching step; after a fix, the graph route did win on a golden set where the entity is named in the query (nDCG@5 0.395 vs the spine’s 0.292). But it still scored zero on procedural, policy-style questions — so the gate still doesn’t pass, and the mode is still off. That’s the correct outcome: a feature earns its place by measurement, or it doesn’t ship. A negative result that changes a decision is worth more than a positive one that flatters a slide.
The numbers I trust least are the perfect ones
Faithfulness came back at 1.000 (18 of 18 answerable queries with zero hallucination), and the judge agreed with my own human labels at a Cohen’s κ of 1.000 (12 of 12). Those look like the strongest numbers in the piece. They’re the ones I’d caution you about hardest.
Both are computed on small, deliberately unambiguous slices. A perfect κ tells me the judge reliably calls the easy cases — it says nothing about the borderline ones, which are exactly where a faithfulness judge earns its keep. And the 1.000 faithfulness includes a few honest “I don’t have enough information to answer” refusals, which are trivially faithful because they assert nothing. The system is genuinely grounded-or-silent by design — but a 1.000 on 18 queries is a floor I’ve shown it can stand on, not a guarantee it always will. The natural next step is a harder, more ambiguous evaluation slice, and I expect those perfect scores to come down. Good.
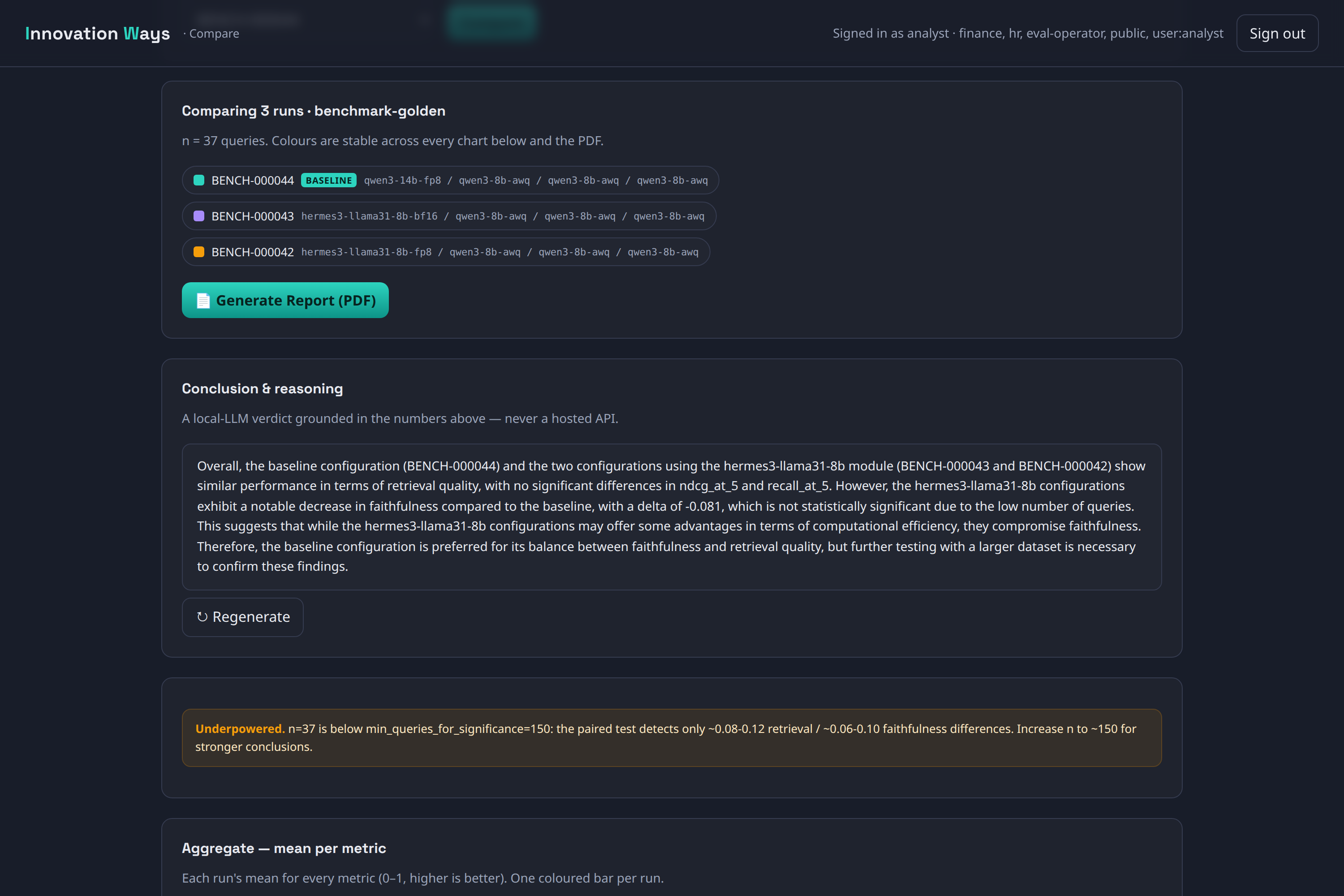
The screenshot above is the comparison view, and it’s the most honest thing in the product. It puts the sample size in the header (n = 37 queries), writes a grounded plain-language verdict from a local model (never a hosted API), and — the part I’m proudest of — prints an orange “Underpowered” box telling you the sample is below the 150 it would need to call a statistically significant winner. The tool argues against over-reading its own output. Under the hood that’s a paired Wilcoxon test with bootstrap confidence intervals and a multiple-comparison correction; on screen it’s just: don’t trust this delta yet.
There’s a security half to all this too — zero cross-tenant access-control leaks across the probes I ran, and a moment where a standard red-team tool over-reported a vulnerability and the studio caught its own measurement error — but that’s an article of its own, and the same honesty rules apply: demo-scale, snapshots not guarantees.
So what’s the actual conclusion?
Not “IW RAG scores 1.000.” The sample is tiny and I built the thing — you should weight a self-run accordingly, which is the entire reason the disclaimer is at the top and not the bottom.
The durable conclusions are the ones that held regardless of the absolute digits, and they’re decisions you can carry to your own system:
- Spend on retrieval, not on a bigger generator. Hybrid search plus a reranker moved the needle; scaling the model didn’t.
- A small, tuned, quantized model is the right default on one GPU. Tuning beat size; 4-bit matched full precision at a fraction of the cost.
- Measure the boring knobs. A kernel flag was a 10× decode speedup hiding in plain sight.
- Keep your negative results. The mode that scored zero taught me more than the ones that passed — and the system that flags its own underpowered samples is the one I’d actually trust at scale.
The model is a commodity; the measurement is not. If you want to see the harness, the corpus design, and every report — including the zero — it’s all in the open.
Sérgio Gaspar is the founder of Innovation Ways — two decades building and owning critical back-office systems, now building modern AI tooling in parallel. He writes about putting AI into places where correctness isn’t optional.