IW RAG
A fully-local, single-GPU agentic RAG system with a benchmarking studio built in — grounded, cited answers over your own documents, and the numbers to prove how well any configuration actually performs.
- Python 3.12
- LangGraph
- vLLM
- pgvector + BM25
- Local · single-GPU
- OSS · MIT

What it is
IW RAG answers natural-language questions grounded in a private document corpus — with inline citations and document-level access control — running entirely on a single machine. No model call ever leaves the box: the generator, the embedder, the reranker, the safety guards, and even the LLM judges are all open-weight and served locally. It is built around one principle — measured, not asserted — and ships a first-class benchmarking studio to prove how well any configuration performs.
How it works
The retrieval spine runs an access-control pre-filter (a caller can never retrieve a chunk they aren’t allowed to see), then hybrid retrieval — dense BGE-M3 vectors over pgvector and BM25 lexical search, fused with reciprocal-rank fusion — then a cross-encoder reranker and small-to-big parent expansion. On top sits an adaptive-RAG agent (LangGraph) that grades its own retrieval and its own generation, re-retrieves when the context is weak, and fails closed — an honest refusal — rather than emit an answer it cannot ground. A single Postgres instance holds the vectors, the lexical index, metadata, ACL tags, and an append-only audit log together, so every answer is one transaction with one trail. Serving is one GPU: vLLM runs the generator, infinity serves the embedder and reranker on the same card, and a swap controller keeps exactly one generator resident — so two models can be A/B-compared without a redeploy.
The benchmark studio
The headline feature is measurement. An operator console lets you assemble a model stack and, before running, a VRAM budget bar tells you whether it fits the card. Each run scores three tiers: deterministic retrieval metrics (recall, nDCG, MRR — no judge needed), judged faithfulness calibrated against human agreement (Cohen’s κ), and reference-based correctness. Latency, throughput, and VRAM footprint are captured per stage. Comparisons are statistical, not anecdotal — paired Wilcoxon / McNemar tests, bootstrap confidence intervals, and a correction for multiple comparisons — and the studio flags a comparison as underpowered when the sample is too small to trust, rather than declaring a winner anyway. Six leaderboards rank configurations on quality, speed, latency, and VRAM efficiency; every report is persisted and exportable as a branded PDF.
Key decisions
- 100% local, air-gap-capable. Every model — including the guards and the judges — is open-weight and served on-box; nothing is sent to a hosted API. The full stack co-resides on a single 32 GB GPU.
- Verification-first, fail-closed. The agent grades its own work and refuses honestly when it can’t ground an answer. The verification layer is the product, not a wrapper around it — the same instinct that runs through everything here.
- Access control as a structural pre-filter. Permissions are enforced before retrieval, not as a post-hoc LLM decision — so a cross-tenant leak is structurally impossible, not merely unlikely. Red-team probes measured a 0.000 leak rate.
- Bias-aware judging. The LLM judges are deliberately chosen from a different model family than the generator, to avoid a model flattering its own output — honest numbers over flattering ones, including documented negative results.
Stack
Python 3.12 · FastAPI · LangGraph · vLLM · infinity · PostgreSQL with pgvector (dense) + ParadeDB pg_search (BM25) + optional Apache AGE (graph) · BGE-M3 embeddings · bge-reranker-v2-m3 · Qwen3 generators (AWQ-INT4 / FP8) · Ragas · DeepEval · NumPy / SciPy (paired statistics) · Microsoft Presidio (PII) · Docling · OpenTelemetry / Phoenix tracing · htmx operator console · Caddy · Docker Compose. Strict mypy, extensive ruff, pytest with testcontainers and Hypothesis property tests.
Status
In active development. Open source under the MIT licence.
Screenshots
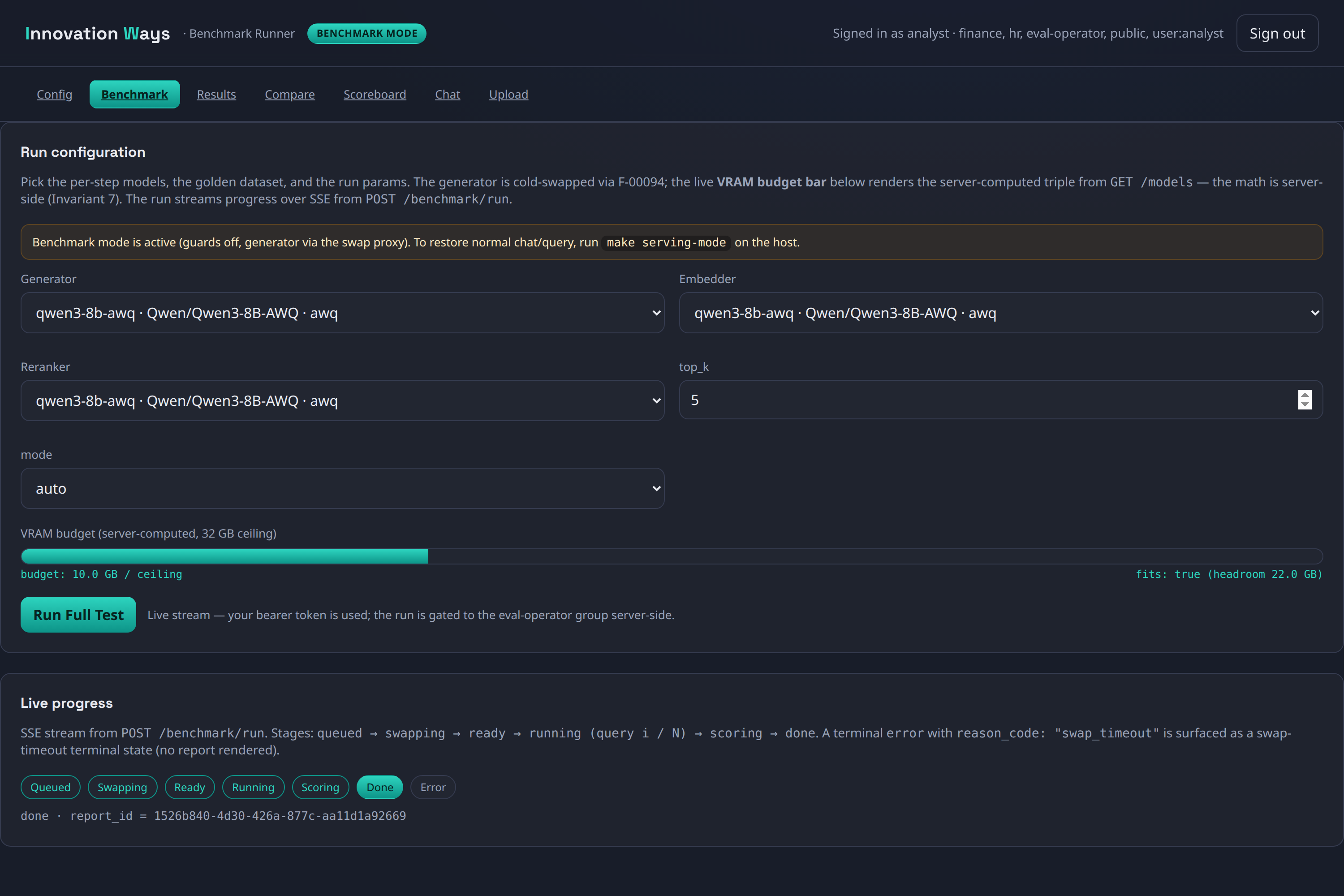
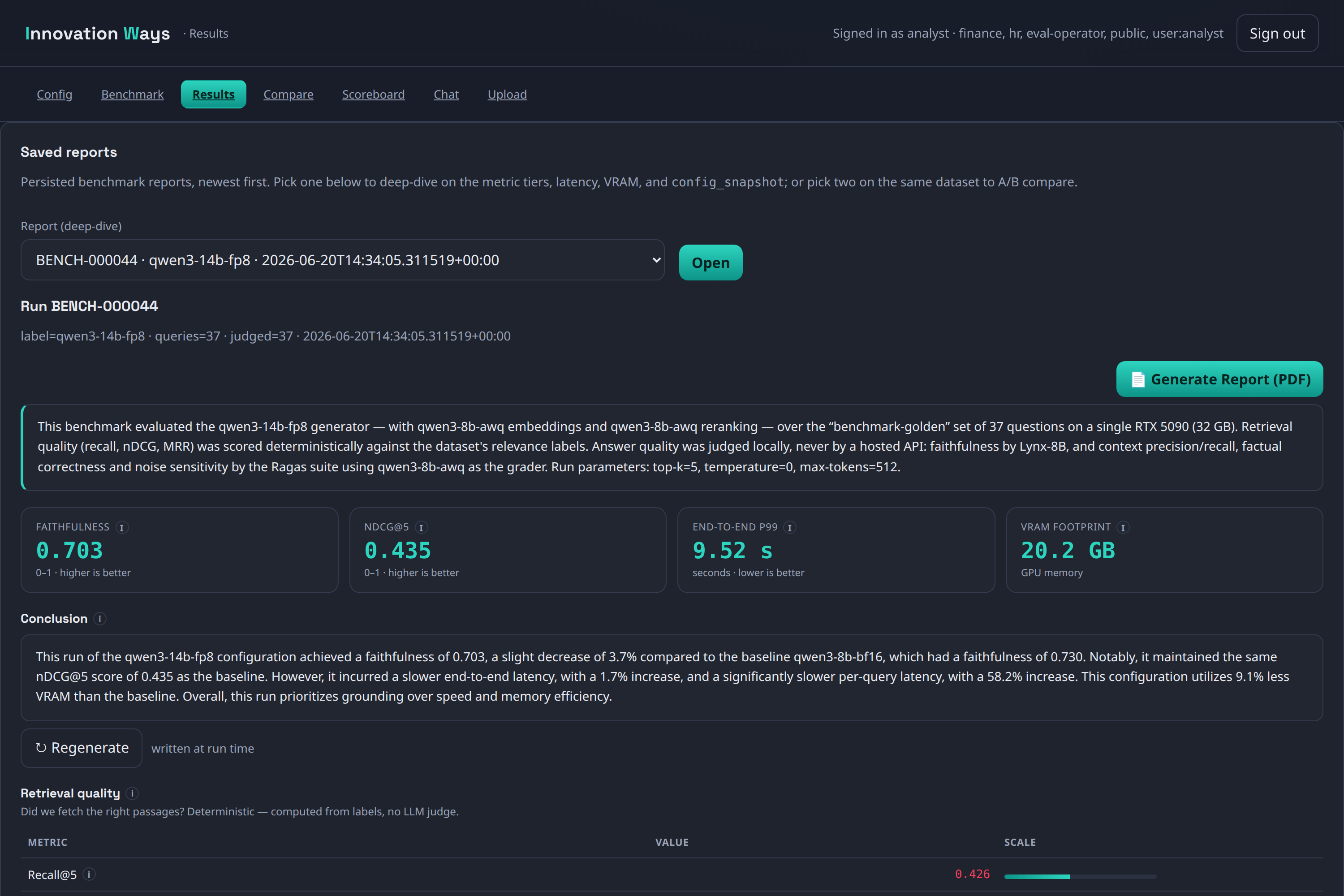
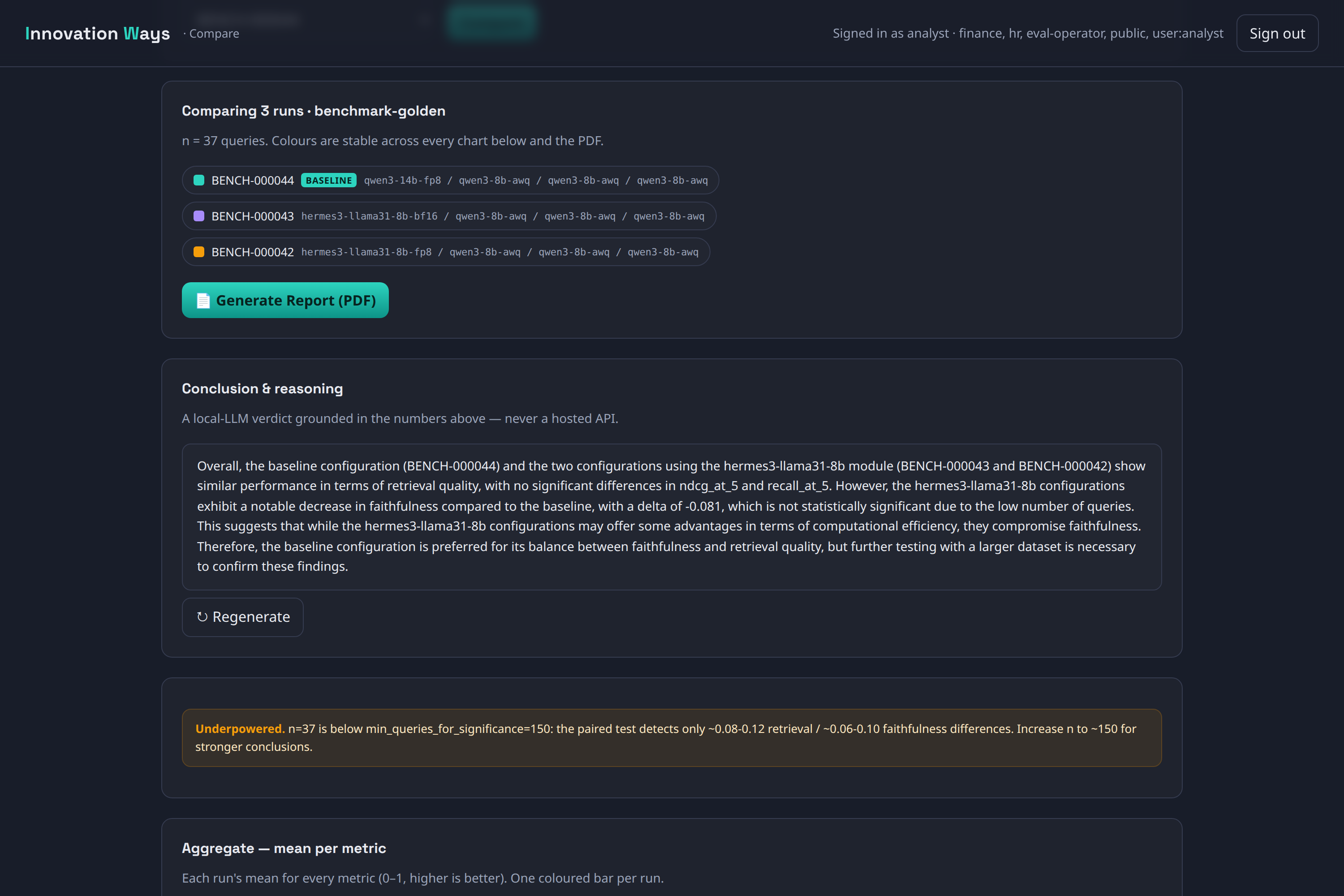
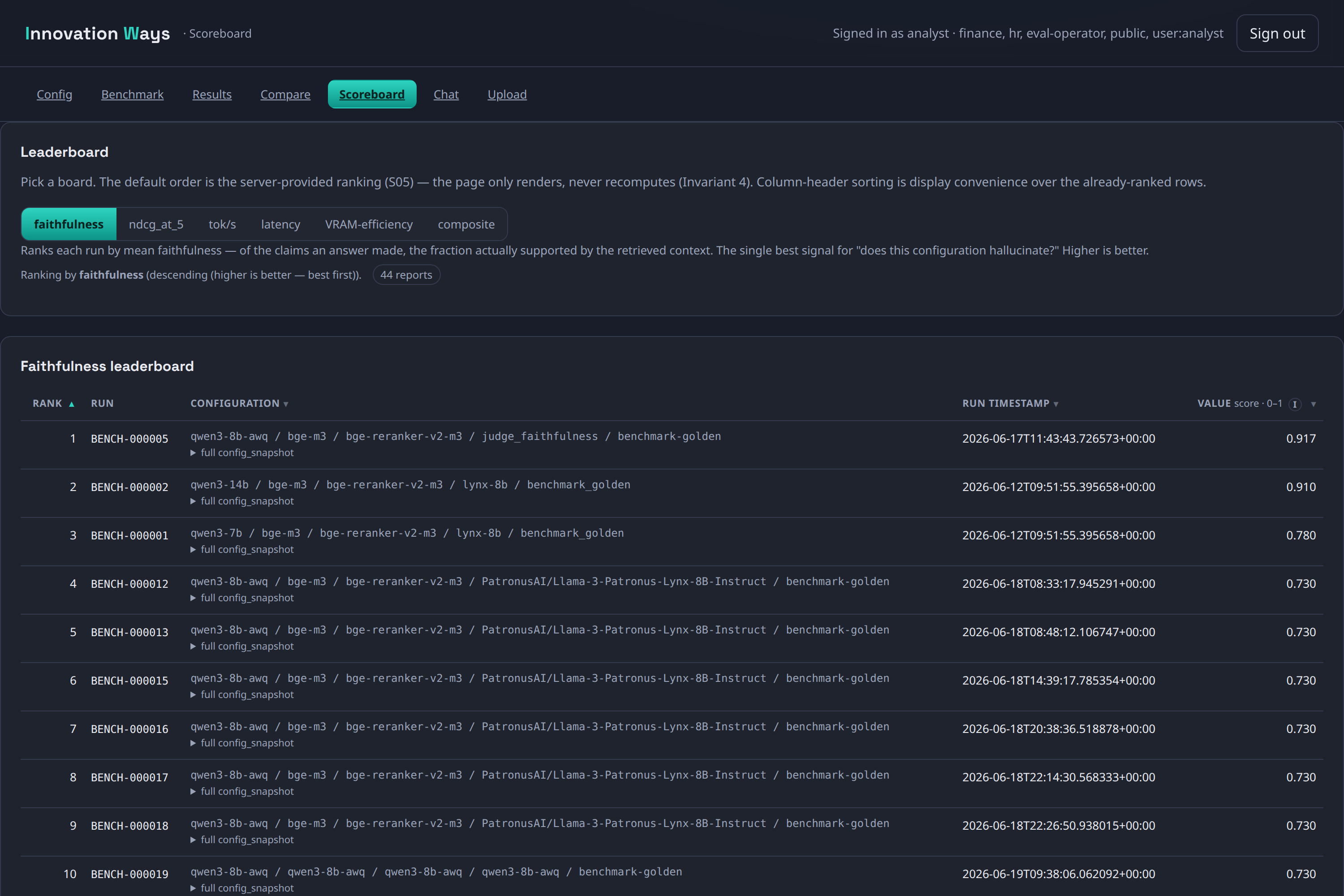
Open source under the Innovation Ways GitHub org .
